JonnhyRDG scripts and snippets
This is a recopilation of some scripts and snippets to automate boring tasks, and some explanations that will go with it.
Rebuilding in Solaris/USD an existing set assembled in Maya (nested references), with python.
Use case: I had a whole city set built in maya, and I wanted to transform it into USD taking advantage of it´s very simple and efficient instance and reference systems.
Also, I didn’t want to manually place a single building, because they are too many and I’m lazy. We’re talking about 200 buildings, and I don’t even know how many other set dressing elements.
To start, I´ll share the code I used inside Solaris, this plus a dictionary extracted from an xml file, is all that´s needed to re build. I’ll explain each python file by phases.
Context. I have a set that is composed of a group of assets. So in that regard, I need to generate each part separately. This parts will be called.
Blocks = groups of buildings/houses.
This is what this “Blocks” look like. Just a couple samples.

City = group of Blocks (plus trees and other elements, that are also grouped). This is what the city looks like:

So this is what the hierarchy looks like.
City
|_Block01_A_01
|_Block01_A_02
|_building01_A_01
|_building01_A_02
And this is a visual representation of how I assembled the set (and yes, I did all that manually because reasons).
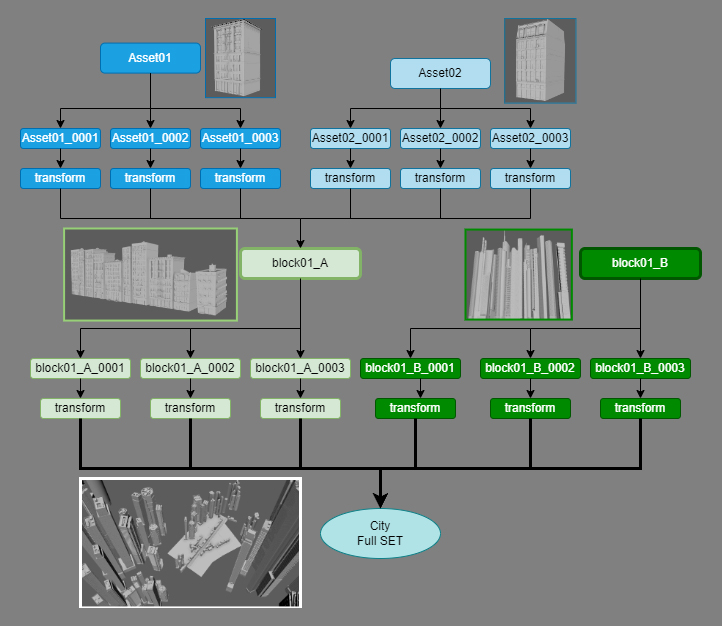
So you’ll see in the python scripts, the first step is to generate the blocks, and then the city.
Step 1: Exporting the XML file from Maya.
Here’s a snippet I got from chatGPT to export xml data with matrices from maya.
It can be customized to export whatever you want from it, but you have to dig into it a bit.
I do have a custom code/api a TD did for me, but this is the gist of it.
import xml.etree.ElementTree as ET
import maya.cmds as cmds
# Create the root element
root = ET.Element("Scene")
# Get a list of all objects in the scene
objects = cmds.ls(type="transform")
# Loop through each object and extract its matrix information
for obj in objects:
matrix = cmds.xform(obj, q=True, matrix=True, ws=True)
obj_element = ET.SubElement(root, "Object")
obj_element.set("name", obj)
matrix_element = ET.SubElement(obj_element, "Matrix")
matrix_text = " ".join(str(value) for value in matrix)
matrix_element.text = matrix_text
# Create an ElementTree and write to a file
tree = ET.ElementTree(root)
output_path = "output.xml"
tree.write(output_path)
print("XML exported successfully.")
Step 2: Extracting and converting the XML data into an easily readable dictionary
import xml.etree.ElementTree as ET
import json
We’ll be using both xml.etree and json modules for this little snippet.
xmlblock = ET.parse("P:/AndreJukebox/assets/sets/city/publish/xml/block_builder.xml")
xmlcity = ET.parse("P:/AndreJukebox/assets/sets/city/publish/xml/city_builder.xml")
Both xmlblock and xmlcity are variables that wrap the xml objects.
And below we’ll create the empty dictionaries that we will fill looping through our xml objects above and combine to write out a json file.
blocksdict = {}
assetdict = {}
Now we’re going to create a function and pass a variable for each XML object we have.
def assetListFromXML(xml):
This will allow us to have a couple of if statements, so according to which xml object we pass, it will act differently.
And now, we’re going to access the root of the xml file, and keep it in a variable. For a better overall understanding on how python process, reads and writes xml files I’d recommend watching this:
Parse XML Files with Python - Basics in 10 Minutes by “max on tech”
Subscribe to the guy by the way, he’s cool.
root = xml.getroot()
So to understand some of the loops below I’ll give a sample of the content of my xml file, or maybe just straight up upload the file later. At least it will be useful to build the dicionary.
Here’s an asset written in the xml.
<scenegraphXML version="0.1.0">
<instanceList>
<instance name="root_loc" type="group">
<xform value="1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0" />
<instanceList>
For each level of hierarchy you can see above, I have to dig into it with a for loop. There will be plenty in different levels.
So here we dive:
for instanceList in root:
for instance in instanceList:
for childInstance in instance[2]:
groupIteration = f'{(int(childInstance.attrib["name"].split(":")[0].rsplit("_",1)[1])):04d}'
if xml == "xmlblock":
group = f'{childInstance.attrib["name"].split(":")[0].rsplit("_",1)[0]}_{groupIteration}'
else:
group = f'{childInstance.attrib["name"].split(":")[0].rsplit("_",1)[0]}'
groupXform = childInstance[1].attrib["value"]
groupasset = f'{childInstance.attrib["name"].split(":")[0].rsplit("_",1)[0]}'
groupusd = f'P:/AndreJukebox/assets/sets/{groupasset}/publish/usd/{groupasset}.usd'
Observe how everything inside
childInstance.attrib["name"]
The xform is in another level inside the instance. Hence the “[1]” and then the attrib name again.
childInstance[1].attrib["value"]
The xform is one of the most important pieces of info, because this is the data that alter we’ll transform in a matrix, to transform, scale and rotate each single object.
And now we arrive to a very very important point. Later on, the usd python api will request a very specific format for the matrix info, which is different from the one you get in an xml. Here’s the difference:
Xform from XML
1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0
Matrix for USD
((1.0,0.0,0.0,0.0),(0.0,1.0,0.0,0.0),(0.0,0.0,1.0,0.0),(0.0,0.0,0.0,1.0))
Yeah I know, it doesn’t look like much, but it matters, and a lot. Thankfully, the format in the Xform in the XML file is consistently separated by “ “. That means that a little loop and a f’ statement is all we need.
First we split the line by spaces, with the python’s split function.
tr = groupXform.split(" ")
That will turn tr in a list of separated values.
Then we’ll create an empty dictionary
tdict = {}
And an iteration variable, you’ll see what for below.
iter = 0
Now what we’re going to do, is to iterate through each value of the list, and assign an index to it. That index will become a dictionary key.
for i in tr:
iter = iter + 1
tdict[iter] = i
This will give us a dictionary that bascially looks like this: tdict = {1:value1},{2:value2}…etc
And then we just have to place each value in the new structure, calling the keys in order:
group_matrix = f'( ({tdict[1]},{tdict[2]},{tdict[3]},{tdict[4]}),({tdict[5]},{tdict[6]},{tdict[7]},{tdict[8]}),({tdict[9]},{tdict[10]},{tdict[11]},{tdict[12]}),({tdict[13]},{tdict[14]},{tdict[15]},{tdict[16]}) )'
And that’s it, we’re now storing all matrices in the correct format. This will be VERY important later.
In this last part of the code, I just do the exact same thing just going in a level deeper. Inception style.
for assetGroups in childInstance[2]:
assetdict = {}
for assetUnit in assetGroups[2]:
assetname = assetUnit.attrib["name"].split(":")
assetclean = assetname[2].rsplit("_",1)[0]
# final info variables
assetpath = assetUnit.attrib["refFile"]
usdassetpath = assetpath.replace(".abc",".usd").replace('publish/cache','publish/usd')
assetInstance = f'{assetclean}_{int(assetname[1].rsplit("_",1)[1]):04d}'
xform = assetUnit[1].attrib["value"]
# Reformat the matrix string for USD
tr = xform.split(" ")
tdict = {}
iter = 0
for i in tr:
iter = iter + 1
tdict[iter] = i
asset_matrix = f'( ({tdict[1]},{tdict[2]},{tdict[3]},{tdict[4]}),({tdict[5]},{tdict[6]},{tdict[7]},{tdict[8]}),({tdict[9]},{tdict[10]},{tdict[11]},{tdict[12]}),({tdict[13]},{tdict[14]},{tdict[15]},{tdict[16]}) )'
assetdict[assetInstance] = {"xform":asset_matrix, "abcpath":assetpath,"usdpath":usdassetpath}
blocksdict[group] = {"xform":group_matrix, "usdpath":groupusd, "assets":assetdict}
if xml == xmlblock:
with open('P:/AndreJukebox/assets/sets/city/publish/xml/block_builder.json', 'w') as blockdict:
json.dump(blocksdict, blockdict)
else:
with open('P:/AndreJukebox/assets/sets/city/publish/xml/city_builder.json', 'w') as citydict:
json.dump(blocksdict, citydict)
assetListFromXML(xml=xmlblock)
assetListFromXML(xml=xmlcity)
Keep in mind all the splitting of strings is quite customized to my particular structure of namespaces and conventions I had in maya (which was a bit messy but I’ve done it years ago, leave me alone) As for the last two lines, I’m calling the functions and passing the different xml files. According to which xml file the function receives, the “if” statements change a couple things. Like the group iterations and which dictionary to write.
So we go from something like this:
<instanceList>
<instance groupType="assembly" name="block01_A_01:block01_A" type="group"><bounds maxx="6915.81224308" maxy="4445.54075834" maxz="5994.64990971" minx="-7318.69642493" miny="-5.48417213559" minz="-7161.32108959" />
<xform value="1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 1.0" />
<instanceList>
<instance name="block01_A_01:am030_01:AM215_030_loc" refFile="P:/AndreJukebox/assets/sets/AM215_030/publish/cache/AM215_030.abc" refType="abc" type="reference"><bounds maxx="980.548404712" maxy="3318.98790847" maxz="-2516.626905" minx="-781.32555769" miny="-0.9227360636" minz="-4477.12873605" /><xform value="0.0 0.0 -1.0 0.0 0.0 1.0 0.0 0.0 1.0 0.0 0.0 0.0 119.738407153 0.0772639364004 -3482.42872384 1.0" /><lookFile ref="P:/AndreJukebox/assets/sets/AM215_030/publish/klf/AM215_030.klf" />
To something like this:
{"block01_A":
{"xform": "( (1.0,0.0,0.0,0.0),(0.0,1.0,0.0,0.0),(0.0,0.0,1.0,0.0),(0.0,0.0,0.0,1.0) )", "usdpath": "P:/AndreJukebox/assets/sets/block01_A/publish/usd/block01_A.usd",
"assets": {"AM215_030_0001": {"xform": "( (0.0,0.0,-1.0,0.0),(0.0,1.0,0.0,0.0),(1.0,0.0,0.0,0.0),(119.738407153,0.0772639364004,-3482.42872384,1.0) )", "abcpath": "P:/AndreJukebox/assets/sets/AM215_030/publish/cache/AM215_030.abc", "usdpath": "P:/AndreJukebox/assets/sets/AM215_030/publish/usd/AM215_030.usd"}
We have now cleaned a bunch of useless namespace, get rid of the bounds which we don’t need, reformat all the matrices and kept information like file location. Which now can be easily accesed in a simple for loop and dictionary keys! This makes our next steps SO MUCH easier! Easy is good. Remember we’re lazy.
Note: just because when I started building this script, I still didn’t have the usd assets published, I kept both, abc and usd files paths. And also because it would be extremely easy to switch between formats since I have both stored.
But now I do have the usds properly published, thank you David Bastidas.
Step 3: Create the blocks for the city. Each block will be its own USD file.
All this below section does is to bring the modules, and wrap the houdini object in a variable so we can access it’s funciones in simple lines later.
### THIS CODE HAS TO BE EXECUTED FROM A PYTHON SCRIPT NODE IN SOLARIS
from pxr import Usd, UsdGeom, Gf
import hou
import json
node = hou.pwd()
Also we’re going to wrap this into a class, in case that’s needed later (spoiler alert, it wasn’). We execute the import of the dictionary we wrote for the blocks, in the init.
class blockbuild():
def __init__(self):
self.dictread()
def dictread(self):
self.citydict = open("P:/AndreJukebox/assets/sets/city/publish/xml/block_builder.json")
self.cityread = json.load(self.citydict)
Let’s go to the juicy part.
In the following loop we’re going to create a usd file pero BLOCK. For this we’re going to loop through our blocks dictionary, and extract the keys. Each KEY is a BLOCK. And each BLOCK will have its usd file to reference later.
Remember! We have to execute this in Solaris, from inside a python script node. As far as I understood, this is so we can act/write in an active stage/layer. But don’t quote me on this, I’m also learning about all this stuff.
def blockslist(self):
for keys in self.cityread:
blockhierarchy = keys.rsplit("_",1)[0]
block_stage = f'P:/AndreJukebox/assets/sets/{blockhierarchy}/publish/usd/{blockhierarchy}.usd'
self.stage = Usd.Stage.CreateNew(block_stage)
group_prim_path = f'/{keys}'
group_prim = self.stage.DefinePrim(group_prim_path,'Xform')
self.createRefs(blocks=keys,refsnum=len(self.cityread[keys]['assets']))
group_model = Usd.ModelAPI(group_prim)
group_model.SetKind("group")
self.stage.GetRootLayer().Save()
# print('________DONE_________')
Create a stage.
We need to create a usd file per block, so that means creating a stage for each one of them.
Which is why it’s inside a loop. I did hardcoded part of the path though.
blockhierarchy = keys.rsplit("_",1)[0]
block_stage = f'P:/AndreJukebox/assets/sets/{blockhierarchy}/publish/usd/{blockhierarchy}.usd'
self.stage = Usd.Stage.CreateNew(block_stage)
self.stage.GetRootLayer().Save()
The blockhierarchy and block_stage variables are just strings. What’s creating the actual stage:
self.stage = Usd.Stage.CreateNew(block_stage)
And this is what’s going to write the file to disk.
self.stage.GetRootLayer().Save()
But I’m getting ahead of my self. Before we save it to disk we need to define the prims and references of each asset inside the block.
So we’re going to define a prim, as you know everything in a USD stage is a prim. So we will also specify what’s the type.
group_prim = self.stage.DefinePrim(group_prim_path,'Xform')
Now we’re basically creating a prim inside our stage. Keep in mind that the prim path has to be absolute. And after the path, we’re telling Solaris that this prim is an “Xform”.
The prim will look like this, for example:
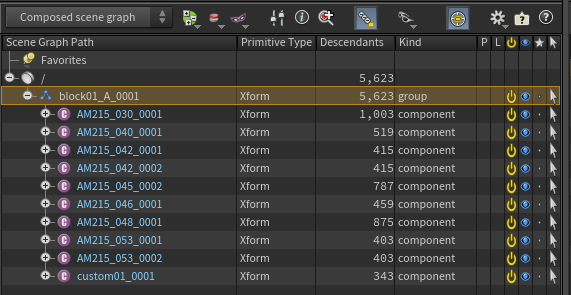
So now that we have a hierarchy for the block, we’re going to reference each asset and place it under it.
def createRefs(self, blocks, refsnum):
iteration = 0
for buildings in self.cityread[blocks]['assets']:
xform = (self.cityread[blocks]['assets'][buildings]['xform'])
assetname = buildings.rsplit("_",1)[0]
new_building = f"/{blocks}/{buildings}"
print(new_building)
So what is this loop doing? Simple. For each block, we’re going to dive in, and format our new prims, and store the xform of each, which we’ll use later.
The print there is so we can keep track of what’s happening.
Ok, so what’s next? As before we’ll define each prim but now for the assets.
new_prim = self.stage.DefinePrim(new_building)
And now we’re going to retrieve the assets usd file with the ‘usdpath’ key in our dictioary.
assetusd = (self.cityread[blocks]['assets'][buildings]['usdpath'])
Below, we’ll actually add the reference, and set it to instanceable.
new_prim.GetReferences().AddReference(assetusd)
new_prim.SetInstanceable(True)
To better understand what’s that for, this is the USD python api way to do exactly the same as this below.

GetReferences().AddReference() is the python equivalent to add a reference and setting the File Pattern.
SetInstanceable(True) is the python equivalent to tick the Make Instanceable checkbox.
At last, we’ll set the prim kind:
building_model = Usd.ModelAPI(new_prim)
building_model.SetKind("component")
Now instead of doing all of that manually, we’ll just store it in ram and write it straight to a usd file. Which will basically look like this.
#usda 1.0
def Xform "block01_A" (
kind = "group"
)
{
def "AM215_030_0001" (
instanceable = true
kind = "component"
prepend references = @P:/AndreJukebox/assets/sets/AM215_030/publish/usd/AM215_030.usd@
)
}
And now we have finally arrived to the part that we didn’t want to do manually. Which is to set the transformations to each individual asset, for form the blocks.
In the last step, we will do the exact same thing to each iteration of the blocks instead of the assets.
First we need to convert our “new_building” string into a usd object.
# assign the matrix to each building
target_path = self.stage.GetPrimAtPath(new_building)
And the turn that object into an xformable object.
xformable = UsdGeom.Xformable(target_path)
Another string we need to convert is the xform, which comes as a string type stored in a dictionary. To turn it into a tuple, we’ll evaluate that string.
transform_matrix = eval(xform)
Next, we’ll convert that tupple into a Matrix4d object that the Gf module will understand as such.
final_matrix = Gf.Matrix4d(transform_matrix)
Final step is to clear our xformable object of any xforms operators it might have and add the transform. Chances are you don’t have any since none has been created before, but sometimes the code fails if you don’t do the clean.
xformable.ClearXformOpOrder()
xformable.AddTransformOp().Set(value=final_matrix)
And now we’ll just execute the function.
blockbuild().blockslist()
And now each asset inside the block will look like this in the resulting usd file.
#usda 1.0
def Xform "block01_A" (
kind = "group"
)
{
def "AM215_030_0001" (
instanceable = true
kind = "component"
prepend references = @P:/AndreJukebox/assets/sets/AM215_030/publish/usd/AM215_030.usd@
)
{
matrix4d xformOp:transform = ( (0, 0, -1, 0), (0, 1, 0, 0), (1, 0, 0, 0), (119.738407153, 0.0772639364004, -3482.42872384, 1) )
uniform token[] xformOpOrder = ["xformOp:transform"]
}
}
See how the matrix4d xform operator has been added to the previous example. That means now we have all the transforms we had in maya, translated and setup in USD referenced prims.
Step 4: Create the city
I could elaborate on this, but basically, this second script is exactly the same as the step above, it just stays in a level above. Since I don’t have to go to the asset level, it has one less loop, and will only work on the blocks level.
Which is what gives us our final City asset, in a single usd file.
Could I merge those two scripts to make it all happen at once. YES I could. Will I? Probably not. I already got what I wanted from this, and I aim to never have to do it again.
But in case I have, it’s documented.
Hopefully for all of you who have sets that would like to bring into usd, this guide will clarify a thing or two.
### THIS CODE HAS TO BE EXECUTED FROM A PYTHON SCRIPT NODE IN SOLARIS
from pxr import Usd, UsdGeom, Gf
import hou
import json
node = hou.pwd()
class blockbuild():
def __init__(self):
self.dictread()
def dictread(self):
self.citydict = open("P:/AndreJukebox/assets/sets/city/publish/xml/city_builder.json")
self.cityread = json.load(self.citydict)
def blockslist(self):
block_stage = f'P:/AndreJukebox/assets/sets/city/publish/usd/city.usd'
self.stage = Usd.Stage.CreateNew(block_stage)
city_prim = self.stage.DefinePrim("/city", "Xform")
city_prim.SetInstanceable(True)
city_model = Usd.ModelAPI(city_prim)
city_model.SetKind("assembly")
for keys in self.cityread:
print(keys)
self.createRefs(blocks=keys,refsnum=len(self.cityread[keys]))
self.stage.GetRootLayer().Save()
print('________DONE_________')
def createRefs(self, blocks, refsnum):
xform = (self.cityread[blocks]['xform'])
assetname = blocks.rsplit("_",1)[0]
block_asset = blocks.rsplit("_",1)[0]
new_block = f"/city/{blocks}"
groupusd = (self.cityread[blocks]['usdpath'])
new_prim = self.stage.DefinePrim(new_block, "Xform")
building_prim = f'/{block_asset}_0001'
new_prim.GetReferences().AddReference(groupusd, building_prim)
new_prim.SetInstanceable(True)
# assign the matrix to each building
target_path = self.stage.GetPrimAtPath(new_block)
xformable = UsdGeom.Xformable(target_path)
transform_matrix = eval(xform)
final_matrix = Gf.Matrix4d(transform_matrix)
xformable.ClearXformOpOrder()
xformable.AddTransformOp().Set(value=final_matrix)
blockbuild().blockslist()
Conclusions:
The most difficult part were the ones that included USD python API, since it’s not that well documented and I don’t have a great understanding of all things usd so far. So maybe it was just me not knowing how to look for stuff rather than poor documentation.

And that’s how the same set can now be shared between dccs. The lookdev is done in Katana, so for now, I’m still using lookfiles. But soon, when a couple of bugs get ironed out in the next release, I’ll export the exact same lookdev in usd, so I won’t need to do that anymore.